Mapping Baobabs, Part 1 - Modelling the Density of Baobab Trees in Zimbabwe with a Linear Model in GEE
This is the first in a multi-part series exploring Species Distribution Modelling (SDM) with the Google Earth Engine. In this post, we’ll take a look at the data we’ll be using, load up some environmental layers and create a simple linear regression model.
Background
Google Earth Engine
Google Earth Engine (GEE) is an amazing tool for working with spatial data on a global scale. By writing some simple javascript, it’s possible to run computations on vast collections of image data thanks to the processing power hiding behind the scenes. Check out https://earthengine.google.com/ for more info.
The Tree
The African Baobab (Adansonia digitata and Adansonia kilima [1]) is an important tree in all countries where it is found. Besides its iconic looks, it provides tasty fruit full of good nutrients [2], bark fibre for crafts [3], traditional medicine [2], shade and an extra source of income [4] in some of the driest and most marginalized communities. Commercialization of the fruit is on the rise, especially for the export market. This is largely due to the fruit’s status as a ‘superfruit’. It’s important that organizations looking to harvest the fruit for sale have good information about the tree population so that they can pick good locations, estimate productivity and make sure that they are not over-harvesting and damaging this incredible resource.
In 2014, I was part of a team that set out to gather said information in Zimbabwe. We travelled all over the country, counting trees, assessing tree health, logging information about tree size and appearance and using questionnaires to find out more about how the trees were viewed and used by the communities who lived near them. This allowed us to produce a good map of the distribution within Zimbabwe, estimate potential yield in different areas and deliver a report on the overall health of the population. We also confirmed the presence of the newly discovered Adansonia kilima [5] - a second species of Baobab on mainland Africa that had only recently been described.
For that project, mapping the density of baobab trees was a tough task. I had to source gigabytes of data (not easy with Zimbabwe’s internet infrastructure), write some custom code to slowly crunch the numbers, tie together my own scripts with add-ons to QGIS (mapping software) and wait days for models to run. As you’ll see in the next few posts, Google Earth Engine makes the job significantly easier.
The data
There are two main types of data used in SDM. One is occurrence data - this can be points or areas where a species is known to occur. This is useful for calculating the probability of occurrence and creating maps showing where a species might be found, but less useful if you are trying to estimate density. The second type is ‘count data’ - the number of frogs in 10m2 or the total number of sightings along a transect. With count data, one can begin to predict how many of something will be found at a given location.
The data we collected in 2014 is count data - all the baobabs along road transects and walked transects were counted and their locations logged. The transects were subdivided into 200m by 200m plots, and each plot has an associated count - the number of baobab trees in that plot. There are 14,683 of these in the dataset, representing nearly 60 thousand hectares sampled. We could have subdivided the transects differently to get fewer, larger plots but we’ll leave that as a subject for a future post.
Loading input layers
Environmental Data
Google Earth Engine has a vast amount of data available with a few clicks. We want to examine all the factors that could affect where a tree grows. You can go really deep here, but since this post is just a first rough pass we’ll grab some climate-related layers and altitude (the latter because every document on baobab mentions that it is important). You could try searching directly for things like temperature, rainfall etc, but conveniently an org [check] called Worldclim has put together 19 variables derived from climate data that they deem “biologically meaningful values”. These include temperature seasonality, max rainfall, etc. Search for ‘worldclim’ and select ‘Worldclim BIO Variables V1’, which will give you a description of the dataset and allow you to import the data. Hit ‘Import’ and give it a sensible name - it will appear at the top of your script.
Add a second import with some elevation data. Elevation data is available in up to 30m resolution, but since we’re working on a large scale and the climate data is 1km resolution, using 30m resolution elevation data is a little overkill, and will slow things down. “ETOPO1: Global 1 Arc-Minute Elevation” is a lower resolution image we can use, or you can resample the high-res layer (see part 3 of this series for examples).
Sampling
We need to create a training dataset that contains both the baobab density (from the count_data file) and the environmental layers (represented by bands in merged_image). Fortunately, GEE has a function to simplify this. We sample the image at each point:
var training = merged.sampleRegions(cd);
Training now contains a list of features. Each looks like this:
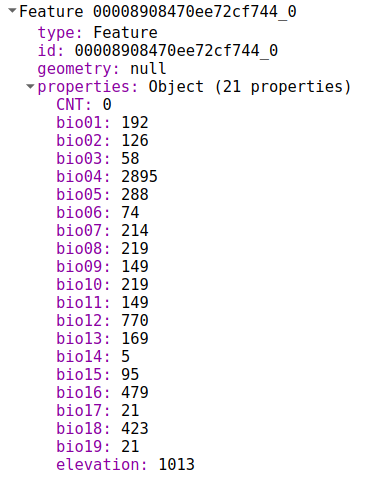
We can use this to train a model
Creating and training the model
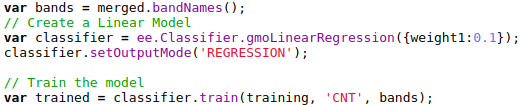
Google Earth Engine provides a variety of models for us to choose from. For this post, we’ll stick to a simple linear model, available via ee.Classifier.gmoLinearRegression. We create the model, set it to regression mode (since we’re predicting density, a continuous variable) and train it with our prepared training data:
The model can now be applied to predict the density in different locations. We can use a different set of points and prepare them the way we did the training data, or we can simply apply the classifier to the whole image. The band names must match (see docs for details). Since we’ll use the merged image used for training, no further prep is needed:
var classified = merged.classify(trained);
Map.addLayer(classified);
Tweaking the visualization parameters gives us our result:

The output can be saved as an asset or exported to Google Drive for later use.
Conclusion
There are many improvements that could be made, but this model is already very useful. Within the study area, it is fairly accurate (we’ll examine this in a future post) and it shows where baobabs can be found, and where we should expect high densities. In the next few posts, we’ll examine some better models, quantify model accuracy, map model applicability (i.e. where the model can be expected to produce useful output), experiment with different sampling techniques and so on.
If you have questions, please get in touch!
You can see a full demo script at https://code.earthengine.google.com/3635e796d66d348c2d3a152430dc1142
References
[1] - Pettigrew, F.R.S., Jack, D., Bell, K.L., Bhagwandin, A., Grinan, E., Jillani, N., Meyer, J., Wabuyele, E. and Vickers, C.E., 2012. Morphology, ploidy and molecular phylogenetics reveal a new diploid species from Africa in the baobab genus Adansonia (Malvaceae: Bombacoideae). Taxon, 61(6), pp.1240-1250.
[2] - Kamatou, G.P.P., Vermaak, I. and Viljoen, A.M., 2011. An updated review of Adansonia digitata: A commercially important African tree. South African Journal of Botany, 77(4), pp.908-919.
[3] - Rahul, J., Jain, M.K., Singh, S.P., Kamal, R.K., Naz, A., Gupta, A.K. and Mrityunjay, S.K., 2015. Adansonia digitata L.(baobab): a review of traditional information and taxonomic description. Asian Pacific Journal of Tropical Biomedicine, 5(1), pp.79-84.
[4] - Alao, J.S., Wakawa, L.D. and Ogori, A.F., Ecology, Economic Importance and Nutritional Potentials of Adansonia digitata (BAOBAB): A Prevalent Tree Species in Northern Nigeria.
[5] - Douie, C., Whitaker, J. and Grundy, I., 2015. Verifying the presence of the newly discovered African baobab, Adansonia kilima, in Zimbabwe through morphological analysis. South African Journal of Botany, 100, pp.164-168.